先进的模式映射
下面是一些可以使用。来执行的高级操作SchemaMapper程序变压器。我们将结合使用属性映射、属性设置和特性类型映射来研究高级筛选。好的模式映射会带来很大的责任,因此我们还将提供一些关于常见错误和调试复杂模式映射的技巧。
下载
多个过滤字段
Filter操作设置了一个“IF语句”类型,FME可以通过它将查找表中的映射与映射应用到的特性匹配起来。在本例中,SchemaMapper将使用多个筛选器属性来定义一个子句。工作空间模板中定义了6个查找表项:
材料类型属性:定义管道材质的属性的名称。材料类型值:管道材料的潜在值。直径属性:定义管道直径的属性的名称。直径值:管道直径的潜在值。状态属性:定义管道状态的属性的名称。状态值:管道状态的潜在值。
在SchemaMapper的查找表参数窗口中,预览窗格显示每个用我们想要用作过滤器的属性值填充的条件句:

步骤1-要使用这些操作,请在SchemaMapper中设置多个筛选器操作。每个过滤器功能动作将处理一对属性和条件值。滤镜功能动作设置如下:
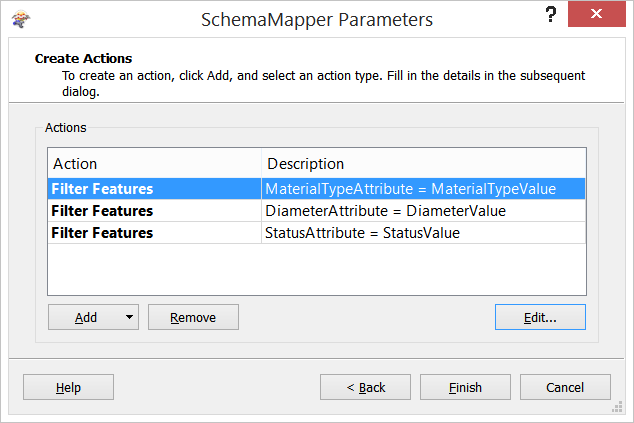
这些操作一起创建了一个条件句:
如果MaterialTypeAttribute = MaterialTypeValue和DiameterAttribute = DiameterValue和StatusAttribute = StatusValue
例如:
如果材料=钢和直径= 300和生命周期状态=活动
使用这组逻辑条件,SchemaMapper现在可以基于多个过滤属性执行转换操作。
设置属性值
除了操作模式类型和属性外,还可以使用SchemaMapper转换器设置属性值。使用SchemaMapper中的“New Attribute”操作,可以将属性及其值添加到数据集,或者修改模式中的现有属性。
例如,设置一个特征的符号学值:
autocad颜色:用于定义要素颜色的属性的名称。颜色:与所需颜色相等的数值autocad_线宽:用于定义要素线宽的属性的名称重量:等于所需线宽的数值。
为了简化映射表,每个属性都作为单独的行添加。查找表中会有更多的行,但是更容易进行编辑。你可以在CSV预览窗口中看到:
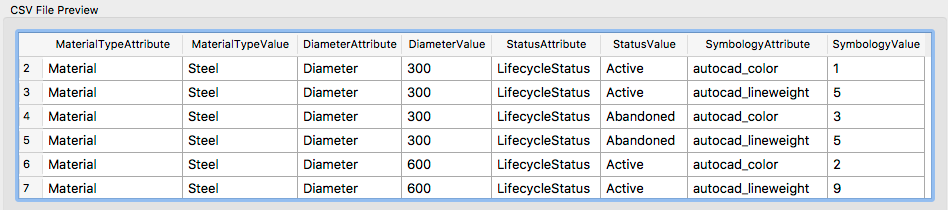
每个组合的类型,直径和地位有两行——每一行代表一个符号属性。这是因为FME不会在它找到的第一个匹配项时停止,而是继续执行它找到的所有映射。此技术使“映射字段”对话框变得简单,因为定义一个映射将设置多个属性。
步骤2-在schemaMapper参数中添加“new attribute”操作。

当与“过滤器功能”操作一起使用时,对话框将如下所示:

最后,当运行工作区时水分配/WMAIN,这将是以下输出:
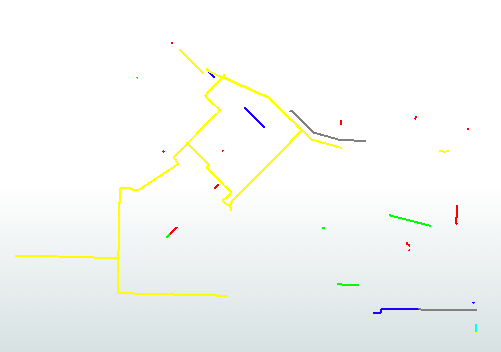
输出数据集中的要素已根据其管道属性(大小、状态、材质)分配了不同的颜色/权重。所有这些都是使用schemaMapper中的三个筛选操作和一个新属性操作完成的。
在表中设置要素类型映射
要素类型映射也可以包含在查找表中。使用format属性功能类型,此示例显示如何将要素类型映射添加为新行,类似于上面创建符号的方式。
例如,要素类型映射已添加到行:
材料,ST,直径,450,生命周期状态,活动,FME U特征U型,小钢管
在schemaMapper预览中如下所示:

然后,可以在工作区中使用扇出或类似方式处理要素类型。
调试SchemaMapper
以下主题讨论使用此转换器时如何解决问题。它包含帮助解决任何可能出现的问题的技巧和技巧。
映射顺序
查找表中的行顺序很重要。fme将继续应用映射,因为它在查找表中是自上而下工作的。例如,给定查找表中的这两行:
材质,钢,直径,450,生命周期状态,激活,autocad颜色,1(红色)材质,钢,直径,450,生命周期状态,激活,autocad颜色,2(黄色)
该功能将首先被指定为红色,然后将被黄色覆盖。
这有助于了解:
1)可能存在导致意外映射的重复子句集。
2)订单可以设置“默认值”。例如,将此行放在查找表的顶部:
材料,钢,,,,autocad颜色,1
“钢”类型的所有特征将与此匹配,并被赋予红色(无论大小或状态)。然后在查找表中,使用直径和生命周期状态将设置为不同的值。因此,输出中仍为红色的所有特征都是与完整过滤器不匹配的特征。这些红色特性可以用作错误检查映射逻辑的方法。换言之,应该首先在查找表中放置不太特定的筛选器,然后再放置更为特定的筛选器。
使用此技术的关键是,它只在catch all高于其他映射时才起作用。如果它在下面,那么它将重置任何已经映射的内容。
3)可以设置辅助映射以简化工作空间。
例如,以这个查找表为例:
材料,钢,新材料,所有管道材料,球墨铸铁,新材料,所有管道材料,PVC,新型,所有管道材料,所有管道,autocad颜色,5
在本例中,某些特征映射到类型所有管道然后输入所有管道映射到蓝色(5在autocad颜色索引中)。该表将所有要素映射到新要素类型,然后将该要素类型映射到新颜色。只有当特征类型映射在颜色映射之前时,这才有效。
选择行属性
schemaMapper转换器添加属性_ schemaMapper_行ID到每个映射的特征。这是映射期间引用的架构表中的行号列表。
在某些情况下,您可能必须减小架构映射表的大小,以仅包含特定功能类型应引用的行,然后再从这些行开始工作。模式表中行的顺序很重要-请参见上文。更一般的过滤器应该放在查找表的第一位,后面跟着更具体的过滤器。
你不必只使用一个schemamamapper。您可以有一个仅用于域值映射的查找表和另一个用于功能类型和属性映射的查找表,并在工作区中包含两个schemaMapper转换器。
小费!
您知道fme函数调用可以嵌入到schemaMapper查找表的value字段中吗?当读取表时,fme将运行它们。例如,可以将值设置为:
@大写(@value(a))
更现代的函数需要包装在@evaluate函数中,如下所示:
@EvaluateExpression(未使用1,
日期时间现在
,未使用2)
这不太可能是一种常见的用法,但它是可以做到的。
下载信息
下载内容如下:
- 地理数据库:温哥华市供水和下水道
- 工作区:Geodatabase->ACAD
- 查阅表格:高级示例
数据属性
此处使用的数据源于温哥华市,不列颠哥伦比亚省。它包含根据开放的政府许可证-温哥华许可的信息。
额外资源
- 条件要素映射博客条目:阴谋家五:哦,多纠结的网啊!(这是在FME2009发布前后发表的一系列博客文章的一部分。内容可能并不完全是最新的,但概念仍然是正确的。)
在这种情况下,我需要解析同一单元格中的多个查找值。我已经成功地实现了上面的解决方案,但是无法通过seam来解决多编码域问题。
例如:
数据表:
| 列1 | 二氧化碳 |
| 一 | 无效的 |
| 2 | 无效的 |
| 1,2个 | 无效的 |
查阅表格:
| COL1代码 | COL1值 |
| 一 | 绿色 |
| 2 | 红色 |
输出表(目标):
| 列1 | 二氧化碳 |
| 一 | 绿色 |
| 2 | 红色 |
| 1,2个 | 绿色,红色 |
有什么想法吗?
我无法创建包含每个组合的查找表,例如。“1,2”,“2,1”,因为我正在处理数以千计的数据集和查找值。

 这应该可以工作,因为具有相同id的特性应该按顺序传递。使用这将意味着聚合器不会“阻止”所有功能。
这应该可以工作,因为具有相同id的特性应该按顺序传递。使用这将意味着聚合器不会“阻止”所有功能。{kind=link}
{kind=link}
谢谢你的回复@标记保险箱亚搏在线
虽然我遇到过非s57数据,是的-这是一个s57任务,我正在试图解决。
S57中有许多属性是列表(L)类型。使用上面的解决方案对于一个列来说是很好的,但是我需要对许多特性类(数百个)上的许多属性进行查找。这将导致有大量的attributesplitter和databasejoiner。