高级架构映射
下面是一些可以利用SchemaMapper程序变压器。我们将结合属性映射、属性设置和特征类型映射来研究高级过滤。伟大的模式映射带来了巨大的责任,因此我们还将提供一些关于常见错误和调试复杂模式映射的提示。
下载
多个筛选字段
筛选器操作设置一种类型的“IF语句”,通过该语句,FME可以将查找表中的映射与应用映射的功能相匹配。在本例中,SchemaMapper将使用多个过滤器属性来定义一个子句。工作区模板中包含的查找表中定义了六项:
材料类型属性:定义管道材质的属性的名称。物料类型值:管道材料的潜在值。。直径属性:定义管道直径的属性的名称。直径值:管道直径的潜在值。状态属性:定义管道状态的属性的名称。状态值:管道状态的潜在值。
在SchemaMapper中的“查阅表格参数”窗口中,预览窗格显示每个条件子句,其中填充了要用作筛选器的属性值:

第一步-要利用这些,请在SchemaMapper中设置多个筛选器操作。每个过滤器特性操作将处理一对属性和条件值。过滤器功能操作应设置如下:
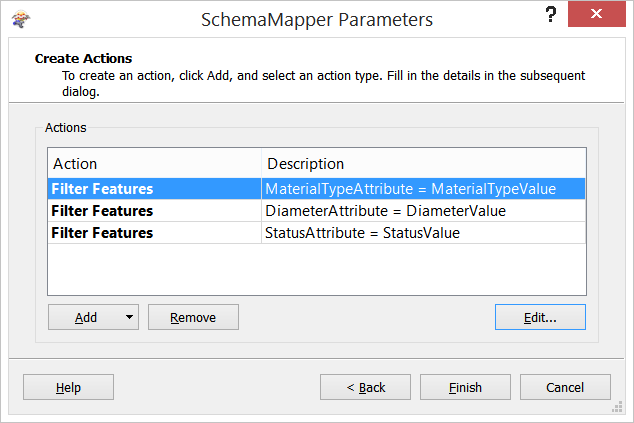
这些操作一起创建了一个条件子句,该子句声明:
如果MaterialTypeAttribute=MaterialTypeValue和DiameterAttribute=DiameterValue和StatusAttribute=StatusValue
例如:
如果材料=钢,直径=300,生命周期状态=有效
使用这组逻辑条件,SchemaMapper现在可以基于多个过滤属性执行转换操作。
设置属性值
除了操纵模式类型和属性之外,SchemaMapper转换器还可以用来设置属性值。使用SchemaMapper中的“newattribute”操作,可以将属性及其值添加到数据集中,也可以修改模式中的现有属性。
例如,设置要素符号的值:
autocad颜色:要在其中定义特征颜色的属性的名称。颜色:与所需颜色等效的数值autocad\u线宽:要在其中定义要素线宽的属性的名称重量:与所需线宽相等的数值。
为了简化映射表,每个属性都作为单独的行添加。查寻表中会有更多的行,但编辑起来会更容易。您可以在CSV预览窗口中看到:
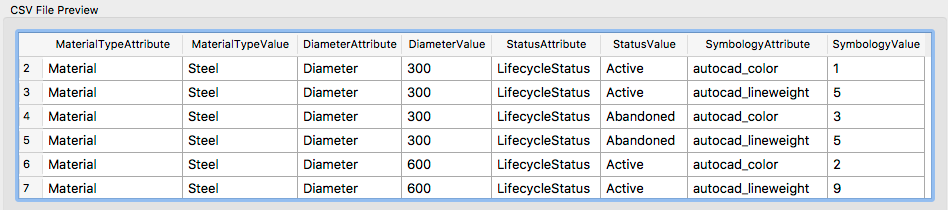
每个组合类型,直径和状态有两行-每个符号属性一行。这是因为FME不会在找到的第一个匹配项时停止,而是继续执行它找到的所有映射。此技术使“映射字段”对话框变得简单,因为定义一个映射将设置多个属性。
第2步-在SchemaMapper参数中添加“newattribute”操作。

当与“过滤器功能”操作一起使用时,对话框将如下所示:

最后,当工作区在配水/wMain,这将是以下输出:
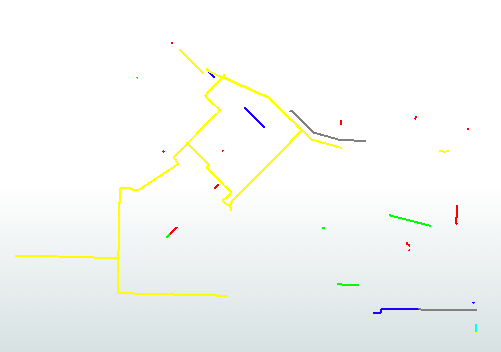
输出数据集中的要素已根据其管道属性(大小、状态、材质)指定了不同的颜色/权重。所有这些都是在SchemaMapper中使用三个过滤器操作和一个新的属性操作完成的。
在表中设置要素类型映射
要素类型映射也可以包含在查找表中。使用格式属性功能类型,此示例演示如何将要素类型映射添加为新行,类似于上面创建符号的方式。
例如,要素类型映射已添加到行中:
材料,St,直径,450,生命周期状态,活性,fme\U特征类型,小型钢管
在SchemaMapper预览中如下所示:

然后可以在工作区中使用扇形输出或类似的工具来处理特征类型。
调试SchemaMapper
以下主题介绍如何解决使用此变压器时出现的问题。它包含了一些技巧和技巧来帮助解决任何可能出现的问题。
映射顺序
查找表中的行顺序很重要。FME将在查找表中自上而下继续应用映射。例如,给定查找表中的这两行:
材质,钢,直径,450,生命周期状态,激活,autocad颜色,1(红色)材质,钢,直径,450,生命周期状态,激活,autocad颜色,2(黄色)
该特征将首先被指定为红色,然后被黄色覆盖。
这有助于了解:
1) 可能有一组重复的子句导致意外的映射。
2) 该顺序可用于设置“默认值”。例如,将此行放在查找表的顶部:
材料,钢,,,,,,,颜色,1
“钢”型的所有特征将与此匹配,并被赋予红色(无论大小或状态)。然后进一步在查找表中,使用匹配的直径和生命周期状态将设置为不同的值。因此,输出中仍为红色的所有特征都是与完整过滤器不匹配的特征。这些红色特征可以用作检查映射逻辑错误的方法。换言之,不太特定的过滤器应该首先放置在查找表中,然后是更特定的过滤器。
使用此技术的关键是,它仅在catch all高于其他映射时才起作用。如果它在下面,那么它将重置任何已经映射的内容。
3) 可以设置辅助映射以简化工作区。
例如,以以下查找表为例:
材料,钢,新材料,所有管道材料,球墨铸铁,新材料,所有管道材料,PVC,新类型,所有管道材料,所有管道,autocad\U颜色,5
在本例中,某些特征映射到类型所有管道然后键入所有管道映射到蓝色(#5在AutoCAD颜色索引中)。该表将所有要素映射到新要素类型,然后将该要素类型映射到新颜色。只有在特征类型映射先于颜色映射的情况下,这才有效。
选择行属性
SchemaMapper转换器添加属性_schemamapper行ID到每个映射的特征。这是架构表中在映射期间引用的行号列表。
在某些情况下,您可能必须减小架构映射表的大小,以便只包含特定要素类型应引用的行,然后从中返回。模式表中行的顺序很重要-请参见上文。在查找表中应首先放置更通用的筛选器,然后再放置更特定的筛选器。
你不必只使用一个SchemaMapper。您可以有一个仅用于域值映射的查找表,另一个用于特性类型和属性映射的查找表,并在您的工作区中包含两个SchemaMapper转换器。
小费!
您知道FME函数调用可以嵌入SchemaMapper查找表的value字段吗?FME将在读取表时运行它们。例如,可以将值设置为:
@大写(@Value(A))
更现代的函数需要包装在@Evaluate函数中,如下所示:
@EvaluateExpression(未使用1,DateTimeNow ,未使用2)
这不太可能是一个常见的用法,但可以做到。
下载信息
下载包含以下内容:
- 地理数据库:温哥华市水和下水道
- 工作空间:地理数据库->ACAD
- 查找表:高级示例
数据属性
这里使用的数据来源于温哥华市,不列颠哥伦比亚省。它包含根据开放政府许可证-温哥华许可的信息。
额外资源
- 条件功能映射博客条目:SchemaMapper V:哦,多纠结的网啊!(这是FME 2009发布前后发表的一系列博客文章的一部分。内容可能不是完全最新的,但概念仍然成立。)
我需要解析同一单元格中的多个查找值。我已经成功地实现了上述解决方案,但无法解决多编码域问题。
例如:
数据表:
| 列1 | Col2公司 |
| 1 | 无效的 |
| 2 | 无效的 |
| 1,2 | 无效的 |
查阅表格:
| COL1代码 | Col1值 |
| 1 | 绿色 |
| 2 | 红色 |
输出表(目标):
| 列1 | col2公司 |
| 1 | 绿色 |
| 2 | 红色 |
| 1,2 | 绿色,红色 |
有什么想法吗?
我无法创建包含每个组合(例如“1,2”、“2,1”)的查找表,因为我正在处理数千个数据集和查找值。
@空间分布它看起来像你试图解决的S57或类似的颜色。
我不认为你可以用SchemaMapper来完成这个。在SchemaMapper中,在查找表中,第二种颜色(红色)将重击第一种颜色(绿色)。
你仍然可以使用查找表,但我认为你必须使用数据库连接程序由一些支持的转换器包围,首先拆分代码列表,然后重新生成结果。像这样:

我附上了示例工作区(2019.0):架构映射.fmwt
在聚合器中,您还应该能够利用新的(2019)Group By Mode参数-Process When Group Changes:
 这应该是可行的,因为具有相同ID的特性应该是按顺序来的。使用这将意味着聚合器将不会“阻止”所有功能。
这应该是可行的,因为具有相同ID的特性应该是按顺序来的。使用这将意味着聚合器将不会“阻止”所有功能。
{kind=link}
{kind=link}